

About a month ago, I wrote a post about the virtues of MySQL 5.6 RC (release candidate), saying that there was no issue and everything would be fine. But now I realize that I spoke too soon. Don’t worry! I’ll explain why, and most users weren’t affected!
First of all, now that MySQL 5.6 is in production (GA – General Availability), it’s a great idea for everyone to migrate their RDBMS to at least version 5.6.10 GA. However, I must say that I still haven’t found evidence that the issue described below has been resolved, given its intermittent nature.
So, MySQL 5.6 brought a range of new features, with replication-related changes standing out. MySQL’s replication has always been a robust and interesting native feature. In MySQL 5.6, the concept of “parallel coworkers” was introduced.
To understand the concept of parallel coworkers, we need to revisit how MySQL replication works internally.
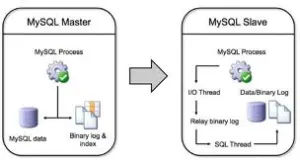
All replication in MySQL is serialized. The Master server (primary) receives and processes several write SQL commands at once, concurrently. These commands are written in an organized manner, one after the other, serially. On the Master server, at the “same time” that the write SQL commands are applied directly to the database, they are also logged in a file called the binary log, which is the foundation for replication in MySQL.
Now, on the SLAVE (secondary server, typically used only for reading), something more interesting happens. Through an internal thread (session) called the I/O Thread, the SLAVE downloads the binary log, creating a new file (or replica) called the relay log. Notice that the only thing that actually happened is the replication of the binary log, now referred to as the relay log. In other words, the write SQL command from the MASTER server is guaranteed to be applied, but has not been applied yet!
Next, a new thread (session) called the SQL Thread is responsible for reading the data from the relay log and applying it to the database. Since the commands are serialized, one command at a time is applied. What’s the problem with this? If four commands, let’s say UPDATE, are applied on the MASTER server on different tables, each taking 5 minutes to execute, the MASTER will execute all four in 5 minutes, because, hypothetically, they arrived at the same time and are processed simultaneously.
However, on the SLAVE, given the architecture of replication, the four commands will take 20 minutes to complete! The first one will execute, and only after its completion will the second one be executed, and so on.
Normally, this is not a huge issue. But depending on the type of application, it can become annoying.
To avoid this problem (phew!), Oracle thought of introducing multiple SQL Threads to apply several write commands, previously logged in the relay log, simultaneously. This functionality was named parallel coworkers. The name is cool and intuitive.
When I did the initial tests, I was very excited about the improvements. But I let myself be guided by the manual. There are some important rules for using parallel coworkers that I’ll leave for another post.
Basically, to configure parallel coworkers, all you need to do is assign a value to the configuration variable: slave_parallel_workers. For example, if you want to have 4 SQL threads running simultaneously, you can configure:
sqlCopiarEditarslave_parallel_workers = 4
As mentioned before, there are some rules and restrictions that need to be considered.
The problem arises when you have configured the replicate-ignore-db variable on your SLAVE. This variable tells the SQL_THREAD: “Hey, don’t apply any write commands related to this specific database!”
Yes… well… okay… that should work. But, with an intermittent irrationality, the parallel coworkers have collided with each other and tried to apply write commands that exist on the MASTER server but don’t exist on the SLAVE server, which is the reason for using replicate-ignore-db.
So, I would like to leave this tip recorded. Apparently, in MySQL 5.6.10 GA, the problem was resolved, or at least mitigated.
Visit our Blog
Learn more about databases
Learn about monitoring with advanced tools
Have questions about our services? Visit our FAQ
Want to see how we’ve helped other companies? Check out what our clients say in these testimonials!
Discover the History of HTI Tecnologia













