
Facebook requires no introduction. I even think there are more people on “the face” than alive in the real world. For many years, Facebook ran and relied on the LAMP platform with Linux, Apache, MySQL-MemCache, and PHP. Over the years, its database grew: 1TB, 10TB, 50TB, 100TB… 200TB, 500TB, and it keeps growing.
In fact, Facebook actively used MySQL up to around 100TB. Ooops, does that mean MySQL can scale up to a 100TB database? Yes and no! Personally, I believe MySQL is very competent, but I wouldn’t feel comfortable with a database larger than 2TB or 3TB. Maintenance difficulty beyond that is very high. Up to 1TB is manageable. But back to Facebook, to achieve the feat of using MySQL with 100TB, they employed thousands of logical “shards” controlled by the application and operating system. Included in the application is not only the website but also the MySQL customized by the internal development team. Customizing MySQL is not for everyone. And it becomes another point of attention… every update from the community and/or vendor must be carefully reviewed by the development team. Managing a dozen logical shards is already a drama—imagine thousands. It’s a lot of “ifs”! “If” the name starts with “A,” data is on this server; “If” the name starts with “C” and lives in the Netherlands, data is on server 1,321! If the developer gets lost in all those “ifs”… only the “f” remains (complete the word)!
KISS – Keep it Simple Stupid! I believe strongly in this! If something is becoming too complex to implement, rethink it!
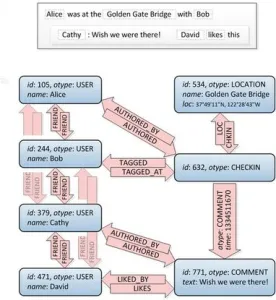
And that’s what Facebook did, creating TAO (“The Association Objects”). TAO is a data store, a database OLAP optimized for reading, geographically distributed, specialized in graph solutions. With enormous storage capacity, but it does not aim to keep consistent bases among its cluster members.
Is TAO big data? Yes, TAO can be seen as a big data engine, like Hadoop and its HDFS. One of its virtues is creating an abstraction layer, as expected of a clustered and distributed storage system, where all the complexity of distributed computing is “hidden” from the programmer. You send a query to the TAO “cloud” and collect the result.
Facebook started exploring the big data world by working with the Hadoop ecosystem, even making a huge contribution by creating Hive and its language HiveQL. HiveQL is an SQL-like language that simplifies using Hadoop. It is still uncertain if TAO will implement HiveQL.
TAO was designed to run distributed and geographically, with data masses in the hundreds of petabytes. And with extraordinary performance: 1.6 billion reads per second and over 3 million writes per second. Tests with MySQL Cluster showed a capacity of up to 1 billion inserts per minute. Can you see how much more optimized TAO is for reading? Obviously, it’s not for writing. Also, as it is “eventually” consistent, dirty reads are common — OLAP folks, OLAP!
TAO primarily runs in memory to boost performance. Facebook published conceptual “papers” on TAO, but not its source code or binaries, and it seems that’s not planned. Anyway, it’s a NoSQL database to watch closely.
Visit our Blog
Learn more about databases
Learn about monitoring with advanced tools
Have questions about our services? Visit our FAQ
Want to see how we’ve helped other companies? Check out what our clients say in these testimonials!
Discover the History of HTI Tecnologia













