

Have you ever wondered how Machine Learning and Artificial Intelligence projects really work in practice? Unlike what many people imagine, it’s not just about training a model with some data and expecting miracles. Every serious ML project follows a rigorous cycle, made up of interconnected stages that range from data collection to maintaining models in production — and unlike traditional projects, it never truly ends.
In this article, you’ll understand in detail the 6 fundamental stages of a Machine Learning project, the challenges in each phase, and key concepts such as overfitting, bias–variance trade–off, and hyperparameter tuning — always from the practical perspective of professionals who work with data in the real world.
1. Collecting the Data to Be Analyzed
This is the foundational stage. Without data, there is no Machine Learning. At this point, we define:
- Where will the data come from? Internal databases, APIs, CSV files, IoT sensors?
- How frequently will data be updated? One-time, daily, or streaming?
- What is the quality of this data? Errors or missing values can jeopardize the entire project.
The more representative the dataset, the better the model’s performance will be. Biased data at this stage leads to biased models in the end.
2. Preparing the Data (Data Preparation)
Raw data is like unrefined ore — it needs processing to become valuable. This step includes tasks like:
- Data cleaning: handling nulls, duplicates, and outliers
- Feature engineering: converting categorical variables, normalizing scales, creating derived columns
- Data splitting: typically into training, validation, and test sets
This is also where we identify and attempt to correct data bias issues.
3. Exploring the Data (Exploratory Data Analysis – EDA)
Before training any model, it’s essential to explore the data. Tools like graphs, correlations, and descriptive statistics help answer:
- Which variables are most relevant?
- Are there linear or non-linear relationships?
- Are outliers influencing the data?
A solid EDA can save weeks of rework later by preventing flawed assumptions in model training.
4. Training the Model (Model Training)
Now comes the “magic” stage: training algorithms to make predictions. Examples include:
- Regression: predicting continuous values (e.g., real estate prices)
- Classification: predicting categories (e.g., whether an email is spam or not)
But beware: this stage is where overfitting and underfitting risks arise.
- Overfitting: the model memorizes training data too well and fails to generalize to new data
- Underfitting: the model is too simple and fails to capture important patterns
The challenge is to find the ideal balance — known as the bias-variance trade-off.
5. Testing the Model (Model Evaluation and Testing)
Time for the truth! The model is tested with data it has never seen. We evaluate metrics like:
- Accuracy
- Precision
- Recall
- F1 Score
- ROC-AUC
Techniques such as cross-validation are also used here to assess the model’s robustness.
6. Deploying the Model (Model Deployment)
Your model may be brilliant, but if it doesn’t run in production, it is useless.
Putting a model into production involves:
- Packaging via APIs, containers, or scheduled jobs
- Monitoring performance (drift, errors, response times)
- Continuous updates and retraining
Model maintenance in production is just as critical as the initial training. A model that works well today may become obsolete tomorrow if the data changes.
Final Touches: Hyperparameters and Tuning
ML models have internal adjustable parameters such as:
- Number of trees in a random forest
- Learning rate in gradient boosting
- Number of layers in a neural network
These are not learned automatically: they’re called hyperparameters and must be tuned using methods like grid search, random search, or Bayesian optimization.
Choosing the right hyperparameters can mean the difference between a mediocre model and a world-class one.
The Cycle Never Ends
Machine Learning is not a project with a beginning, middle, and end. The environment changes, data changes, user behavior changes — and your model needs to keep up.
That’s why we call it a lifecycle. Here’s the cycle visualized:
Machine Learning Lifecycle
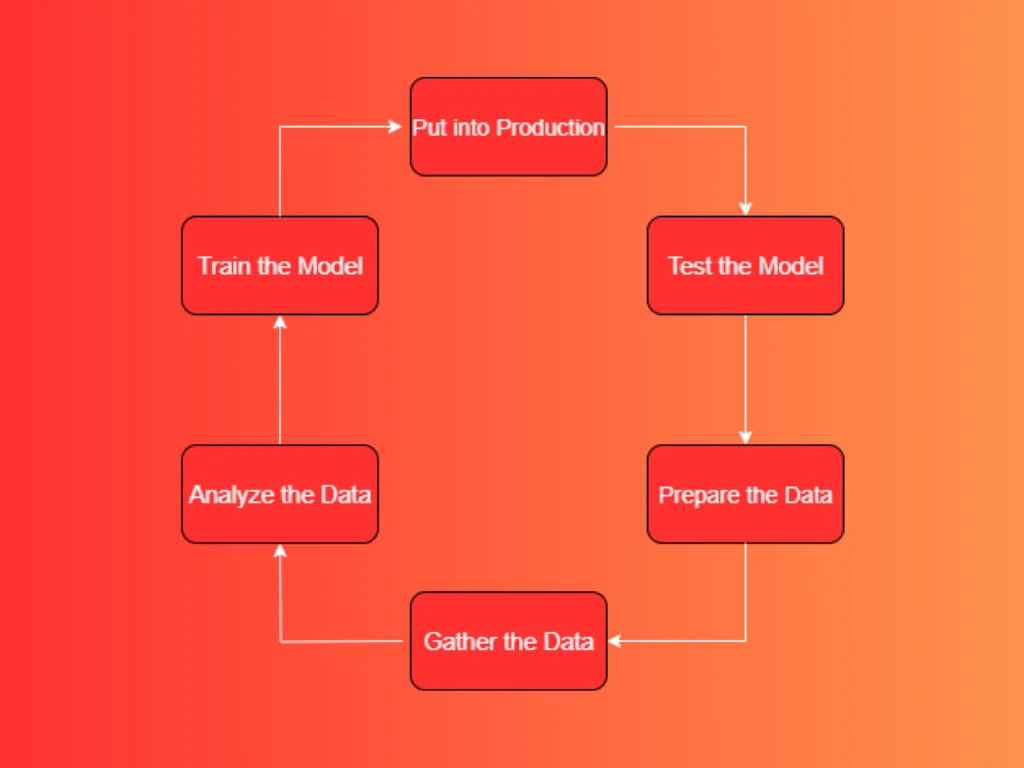
Every time you collect new data, the cycle begins again. The more automated this cycle is, the healthier your ML project will be.
HTI Can Help at Every Stage of the Cycle
At HTI Tecnologia, we believe that successful Machine Learning projects depend on a well-structured and closely monitored cycle. We combine expertise in databases, scalable infrastructure, and certified data science professionals to support your company at every stage — from data collection to model deployment.
Whether you’re just starting a Machine Learning project or need to improve an existing one, talk to an HTI specialist and see how we can accelerate your results safely and efficiently.
Visit our Blog
Learn more about databases
Learn about monitoring with advanced tools
Have questions about our services? Visit our FAQ
Want to see how we’ve helped other companies? Check out what our clients say in these testimonials!
Discover the History of HTI Tecnologia













