

Você já se perguntou como projetos de Machine Learning (Aprendizado de Máquina) e Inteligência Artificial, realmente, funcionam na prática? Diferente do que muitos imaginam, não se trata apenas de treinar um modelo com alguns dados e esperar milagres. Todo projeto sério de ML segue um ciclo rigoroso, composto por etapas interligadas que vão desde a coleta de dados até a manutenção de modelos em produção — e que, ao contrário de um projeto tradicional, nunca termina de verdade.
Neste artigo, você vai entender em detalhes as 6 etapas fundamentais de um projeto de Machine Learning, os desafios de cada fase e os conceitos-chave como overfitting, bias-variance trade-off e hyperparameter tuning — sempre com a visão prática de quem trabalha com dados no mundo real.
1. Reunir os Dados que Serão Analisados
Essa é a etapa fundacional. Sem dados, não há Machine Learning. É aqui que definimos:
- De onde virão os dados? Bancos de dados internos, APIs, arquivos CSV, sensores IoT?
- Com que frequência os dados serão atualizados? Pontual, diário, streaming?
- Qual a qualidade desses dados? Dados com erros ou faltantes podem comprometer todo o projeto.
Além disso, é importante entender que quanto mais representativo for o conjunto de dados, melhor será a performance do modelo. Dados enviesados aqui resultarão em modelos enviesados no fim.
2. Preparar os Dados (Data Preparation)
Dados brutos são como minério antes de virar ouro. Aqui entram tarefas como:
- Limpeza de dados (data cleaning): tratamento de valores nulos, duplicados, outliers.
- Transformações (feature engineering): converter variáveis categóricas, normalizar escalas, criar novas colunas derivadas.
- Divisão dos dados: geralmente em training set (conjunto de treino), validation set (validação) e test set (teste).
É nesta fase que também identificamos e tentamos corrigir problemas de bias (viés) nos dados.
3. Analisar os Dados (Exploratory Data Analysis – EDA)
Antes de treinar qualquer modelo, é fundamental explorar os dados. Ferramentas como gráficos, correlações e estatísticas descritivas ajudam a responder:
- Quais variáveis são mais relevantes?
- Existem relações lineares ou não lineares?
- Há outliers influenciando os dados?
Um bom EDA pode economizar semanas de retrabalho em fases futuras, pois evita que se treine modelos baseados em suposições erradas.
4. Treinar o Modelo (Model Training)
Agora sim entramos na fase “mágica”: treinar algoritmos para fazer previsões. Alguns exemplos:
- Regression (Regressão): prever números contínuos (ex: preço de imóveis)
- Classification (Classificação): prever categorias (ex: e-mail é spam ou não)
Mas atenção: aqui mora o perigo do overfitting e do underfitting.
- Overfitting (sobreajuste): o modelo aprende tanto os detalhes dos dados de treino que se torna incapaz de generalizar para novos dados.
- Underfitting (subajuste): o modelo é tão simples que não consegue capturar padrões relevantes.
O desafio é buscar o equilíbrio ideal — conhecido como bias-variance trade-off (compromisso entre viés e variância).
5. Testar o Modelo (Model Evaluation and Testing)
Hora da verdade! O modelo é testado com dados nunca vistos antes. Avaliamos métricas como:
- Accuracy (Acurácia)
- Precision (Precisão)
- Recall (Revocação)
- F1 Score
- ROC-AUC
Também é aqui que usamos técnicas como cross-validation (validação cruzada) para avaliar a robustez do modelo.
6. Colocar em Produção (Model Deployment)
Seu modelo pode ser genial, mas se não rodar em produção, ele é inútil.
Colocar um modelo em produção envolve:
- Empacotamento via APIs, containers ou jobs agendados
- Monitoramento de performance (drift, erros, tempo de resposta)
- Atualizações e retreinamento constante
A manutenção de modelos em produção é tão crítica quanto o treinamento inicial. Um modelo que funcionava bem hoje pode ficar obsoleto amanhã se os dados mudarem.
Ajustes Finais: Hyperparameters e Tuning
Modelos de ML têm parâmetros internos ajustáveis, como:
- Número de árvores em uma random forest
- Taxa de aprendizado em gradient boosting
- Número de camadas em uma rede neural
Esses parâmetros não são aprendidos automaticamente: são chamados de hyperparameters (hiperparâmetros) e precisam ser ajustados com técnicas como grid search, random search ou Bayesian optimization.
Uma boa escolha de hiperparâmetros pode ser a diferença entre um modelo medíocre e um de classe mundial.
O Ciclo Nunca Termina
Machine Learning não é um projeto com começo, meio e fim. O ambiente muda, os dados mudam, os comportamentos mudam — e o modelo precisa acompanhar isso tudo.
É por isso que falamos em ciclo de vida (lifecycle). Veja o diagrama abaixo:
Ciclo de Vida do Machine Learning
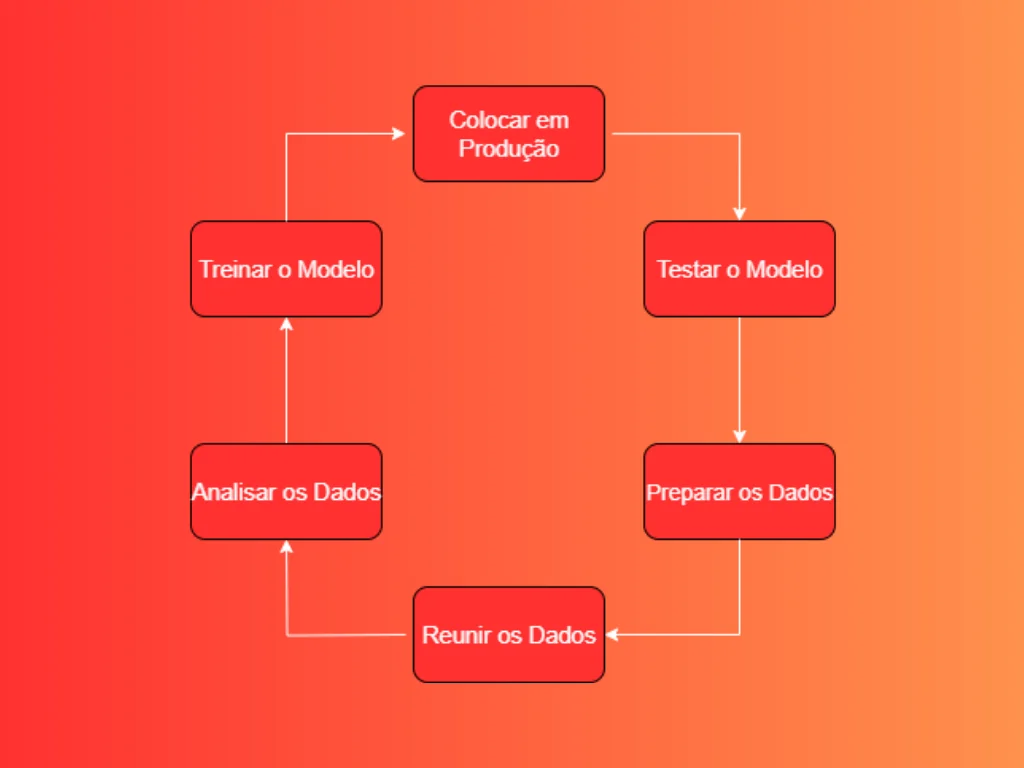
Cada vez que você coleta novos dados, o ciclo recomeça. Quanto mais automatizado esse ciclo, mais saudável seu projeto será.
A HTI Pode Ajudar em Cada Fase do Ciclo
Na HTI Tecnologia, acreditamos que projetos de Machine Learning de sucesso dependem de um ciclo bem estruturado e monitorado. Combinamos expertise em bancos de dados, conhecimento em infraestrutura escalável e profissionais certificados em ciência de dados para apoiar sua empresa em cada etapa — da coleta de dados ao modelo em produção.
Se você está iniciando um projeto de ML, ou precisa evoluir o que já tem, fale agora com um especialista da HTI e veja como podemos acelerar seus resultados com segurança e eficiência.
Visite nosso Blog
Saiba mais sobre bancos de dados
Aprenda sobre monitoramento com ferramentas avançadas
Tem dúvidas sobre nossos serviços? Acesse nosso FAQ
Quer ver como ajudamos outras empresas? Confira o que nossos clientes dizem nesses depoimentos!
Conheça a História da HTI Tecnologia













